Die Zentralbibliothek Zürich scannt mit Google Books
Steht der Untergang des Abendlandes nun bevor? (Wahrscheinlich nicht.) Schaffen Bibliotheken sich nun endgültig ab? (Mitnichten!) Nichtsdestotrotz löst die Kooperation zwischen einem der grössten Tech-Unternehmen der Welt und einer Bibliothek wenn nicht Befremden, so doch eine gewisse Skepsis aus. Doch worin besteht diese Kooperation überhaupt?

Digitalisat von Google Books, «Puck» 1895, Signatur: YX 1906: z | G

Digitalisat von Google Books, «La divina commedia», Signatur: ZP 415

Digitalisat von Google Books, «Florilegium», Signatur: Z 10

Digitalisat von Google Books, «Kikeriki» (1884), Signatur: YX 1907: z

Digitalisat von Google Books, «Digt- Sang- en Speel-Konst», Signatur: 21.199
Die seit 2010 laufende schweizerische Kooperationsplattform e-rara für digitalisierte Alte Drucke, Musikalien, Graphiken und Karten hat im April 2023 die Marke von 100'000 digitalisierten Objekten geknackt! Das ist super! In Zeiten softwareunterstützter Massendigitalisierung von Büchern fällt die Zahl jedoch – gemessen an den verfügbaren Beständen – gering aus, handelt es sich bei der Retrodigitalisierung doch um ein ressourcenintensives Unterfangen, das kostspielige Hardware, technische Infrastruktur, massive Datenverarbeitungs- und Speicherkapazitäten sowie personelle Ressourcen voraussetzt. Die ZB Zürich ist daher 2019 zusammen mit drei weiteren Schweizer Bibliotheken (UB Bern, ZHB Luzern, UB Basel) eine Public Private Partnership mit Google zur Digitalisierung ausgewählter Bestände eingegangen. Im Rahmen dieser Zusammenarbeit sollen über 300'000 Bücher innert kurzer Zeit digitalisiert und der Allgemeinheit und Forschung zur Verfügung gestellt werden.
Das Projekt Google Books
Im Jahr 2005 als «Google Books Search»-Projekt gestartet, umfasst die Plattform «Google Books» heute über 40 Millionen Bücher in digitalisierter Form (Stand 2019), auf die kostenfrei und von überall zugegriffen werden kann. Während in den USA anfangs shelf-cleaning-scanning betrieben wurde, d.h. ganze Magazine von A-Z durchgescannt wurden, ohne Rücksicht auf Urheberrechte oder Kollektionszugehörigkeit, werden heutzutage – nach einer Reihe juristischer Auseinandersetzungen – vor allem Inhalte von Verlagspartnern und konfliktarme Bestände von Partnerbibliotheken gescannt. Anders verhält es sich in Rahmen der Public Private Partnerships mit den europäischen Bibliotheken: diese lassen ausschliesslich ihre urheberrechtsfreien Bestände von Google digitalisieren. Während Google somit permanent mit Büchern durch die Bibliotheken versorgt wird, profitieren die Bibliotheken ebenfalls in mehrfacher Hinsicht: ein (Teil-)Bestand ist digital verfügbar, der Link zu Google Books kann im Katalog implementiert werden, die Scans werden mit OCR erschlossen und die finanziellen Aufwendungen halten sich im Rahmen, da Google für den Transport, die Versicherung und die Digitalisierung der Bücher und die Prozessierung der dabei entstandenen Daten (Bildbearbeitung, OCR, Metadaten) aufkommt.
Projektkooperation Google Books mit Schweizer Bibliotheken
Als vergleichsweise «späte» Partner des Google Books Projekts, operieren die Schweizer Bibliotheken mit sogenannten «Candidate Lists», die diejenigen von Google vorselektierten Bestände einer Bibliothek umfassen, welche noch nicht auf Google Books verfügbar sind. Im Fall der ZB Zürich enthält diese Liste ca. 160'000 Titel, von denen – vorbehaltlich der konservatorischen Vorkontrolle – ein Grossteil in den nächsten etwa zwei Jahren digitalisiert wird. Um bei diesen Mengen einen Überblick zu behalten, nutzen wir die Workflowsoftware der Firma ImageWare. Diese bildet den Prozess vom Ausheben der Bücher im Magazin mit Laufzetteln, über die Abwicklung der benötigten Dokumente für den Zoll, sowie Reports (Metadaten, Bücherlisten) für Google, bis zur Einspielung der Links zu den fertig digitalisierten Büchern auf Google Books ab.

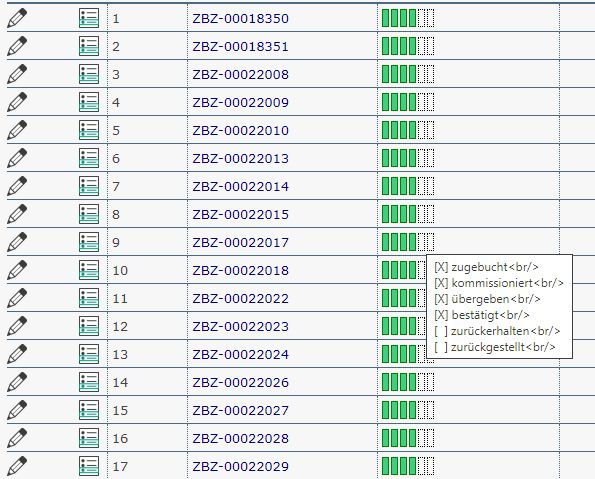
Vorgang ZB Zürich
Unser tatkräftiges Magazinerteam hebt die Bücher anhand der Liste aus und kontrolliert die formalen Bedingungen (Grösse, Breite, grober Zustand des Buches, Kurz-Metadaten). Bei der konservatorischen Vorkontrolle durch unsere Restauratorinnen werden die Bücher auf ihren Zustand (Schäden, Öffnungswinkel) überprüft und entweder geflickt oder aus dem Workflow genommen. Anschliessend werden die für den Versand vorgesehenen Bücher in der Workflowsoftware in einer Charge verbucht, verpackt und beschriftet. 20 Chargen à ca. 250 Bücher ergeben jeweils eine Lieferung von etwa 5000 Büchern, die monatlich nach München ins Scanzentrum von Google transportiert, gescannt und wieder zurückgeliefert wird. Da die Bücher dabei die Grenze von einem nicht-EU-Land und der EU passieren, muss für jede Lieferung ein Zolldokument (Carnet ATA) von der Handelskammer Zürich ausgestellt werden, um die Zollrichtlinien zu erfüllen.


Scanning und Image Processing
In München werden die Bücher an von Google selbst entwickelten Scanstationen digitalisiert und die Bilder maschinell weiterverarbeitet. Zum Anfertigen der Scans wird jede Doppelseite (je die rechte und linke Seite) von zwei hochauflösenden Kameras fotografiert sowie von oben mit einer Infrarotkamera erfasst. Ein spezieller Algorithmus fügt die fotografierten Bilder zu einem dreidimensionalen Bild zusammen, welches anschliessend «flach» gerechnet wird, wobei der Eindruck einer planen Seite entsteht. Weitere Prozessschritte umfassen die Beschneidung der Ränder (Cropping), die Anpassung der Kontraste, die Retuschierung der Finger, die Konvertierung der Farben in Graustufen. In einem weiteren Prozess werden die Metadaten aufbereitet: zusammengehörige Bände werden einer Reihe/Ausgabe zugewiesen (Clustering).
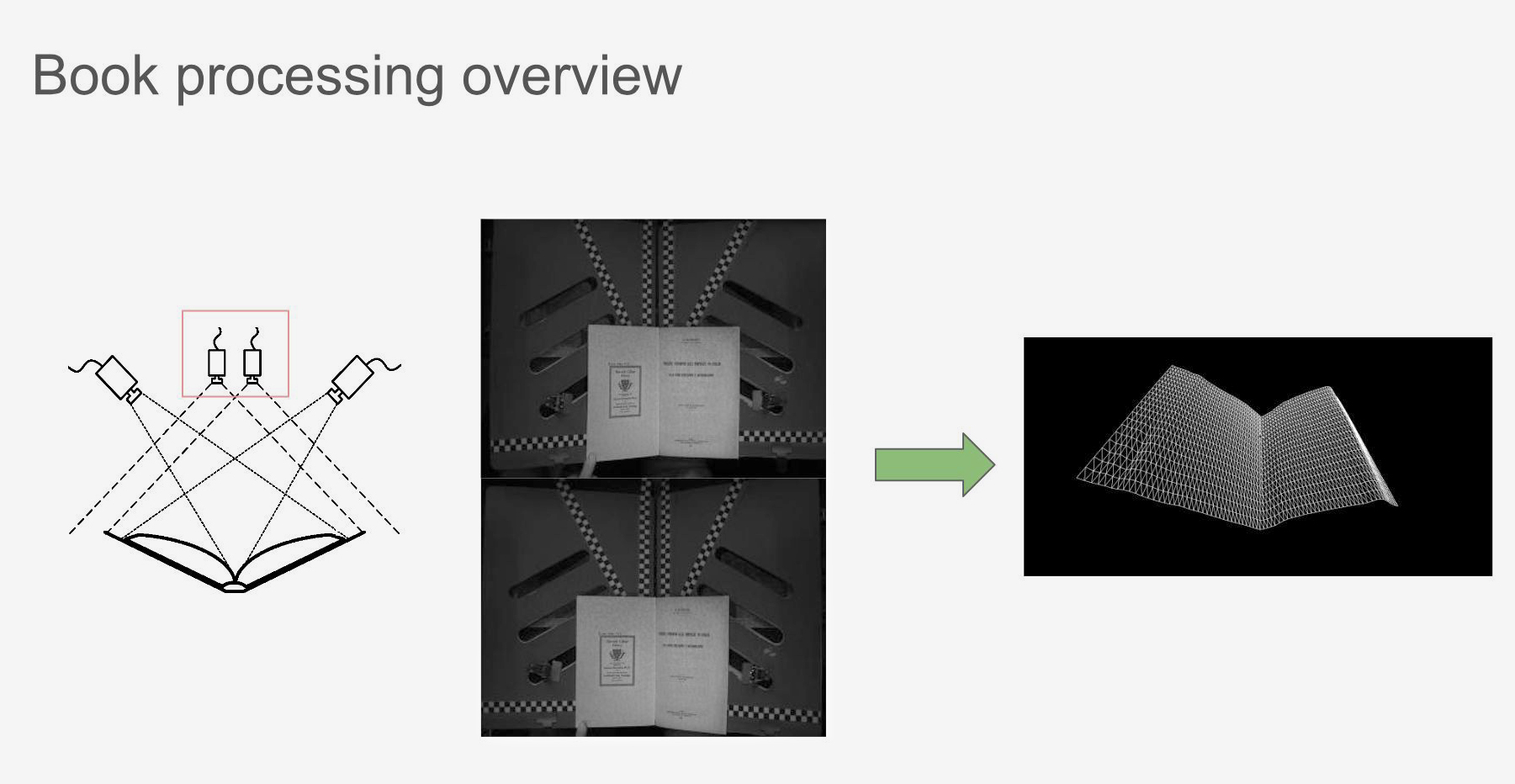
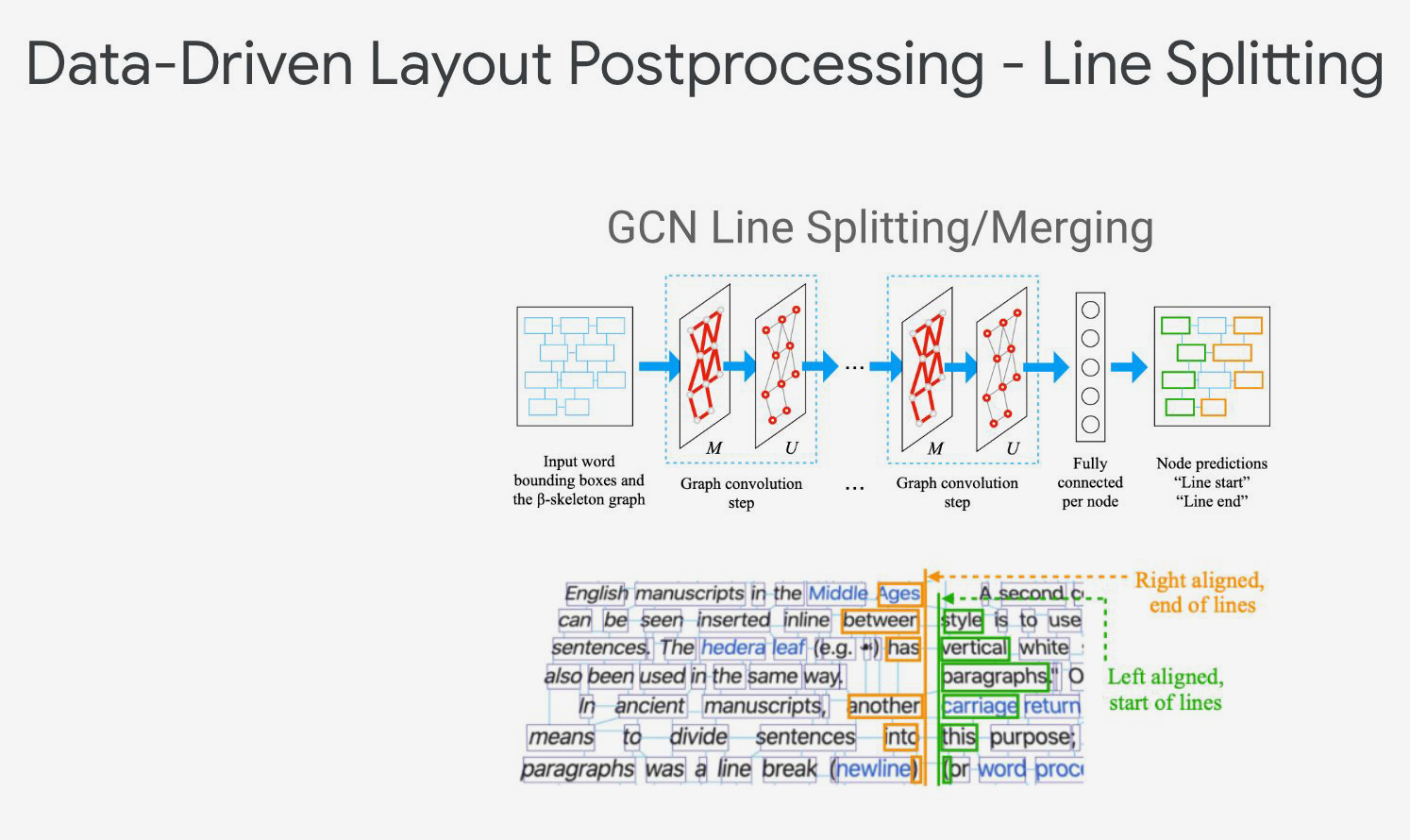
OCR
Den für die Suche fundamentalsten Schritt trägt die Texterkennung bei. Bei der Durchführung der «Optical Character Recognition» (OCR) hat Google zuletzt wesentliche Fortschritte erzielt, so dass heutzutage etwa 60 Sprachen vollständig und knapp 40 teilweise unterstützt, ausserdem diverse Alphabete (arabisch, griechisch, thai, japanisch, lateinisch, und diverse weitere) und teils handschriftliche Systeme erkannt werden. Um Text aus Bildern identifizieren zu können, wird zunächst das Layout einer Seite und die Schriftrichtung analysiert. Die separierten Zeilen, Spalten und Wörter werden auf Schrift(en) und Stil(e) untersucht. Verschiedene Datenmodelle (Multi-Script Recognizer, n-Gram Language Model, Graph Convolutional Networks, Layout Postprocessing) berechnen sodann unter Einbeziehung diverser Parameter die wahrscheinlichsten «Übersetzungen» eines Scans, indem Satzanfang- und Ende, Sprache(n), Schrift, Zeilenlänge, Absatz- oder Spaltenanfang sowie -Ende, Leseweg und Füllmaterial (Bilder, Verschmutzungen, Nicht-Text) erkannt und mit den Datenmodellen abgeglichen werden. Daraus entsteht im Optimalfall ein beinahe fehlerfreier, maschinenlesbarer Text, der Suche und Text Mining begünstigt.
Nutzerstatistik und Beispiele aus unserem Bestand
Beim ersten aus unserem Bestand auf Google Books aufgeschaltete Buch handelt es sich um die 1895-er Ausgabe der Zeitschrift «Puck». Inzwischen sind tausende weitere Bücher aufgeschaltet worden. Die beiden aus unserem Bestand bisher beliebtesten Buch sind Rime sowie Tercüme-i Sihah il-Cevheri, wie uns ein Blick auf unsere interne Nutzerstatistik verrät.
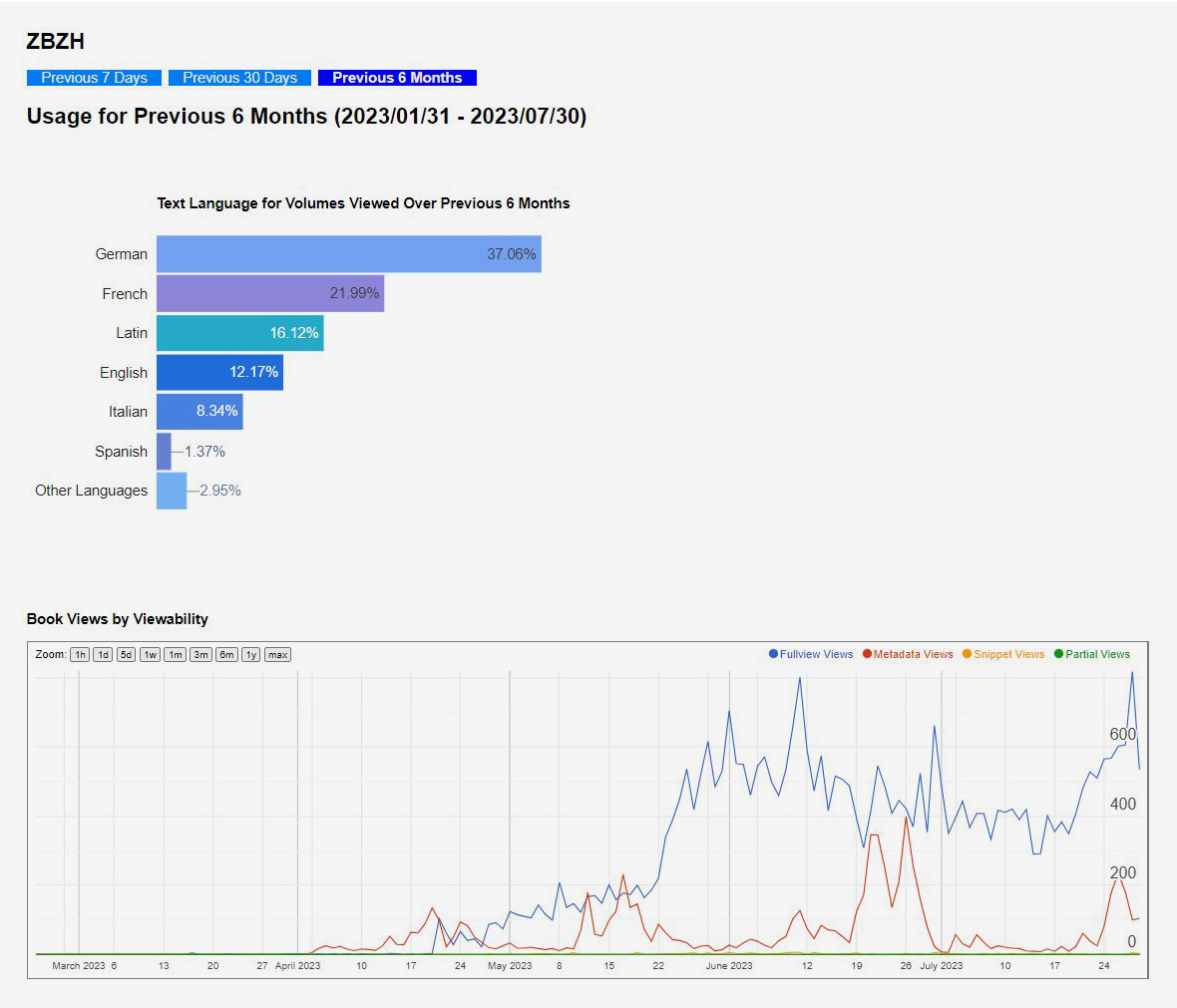

Qualität
Gemessen an den Qualitätsstandards, an welchen e-rara sich orientiert, schneiden die Google-Digitalisate im Gesamtpaket grösstenteils schlechter ab (Qualität der Scans und der Vorschau, Metadaten), die technischen Innovationen und sukzessive Re-Prozessierung der Daten schliessen die Lücke allerdings merklich.


Ausblick
Neben der verbesserungswürdigen Qualität der Metadaten und Scans, besteht ein noch grosses Potenzial in Bezug auf die freie Zugänglichkeit der Bilder und Daten für die Forschung. Das Google n-gram-Tool zeigt, welche Spielereien mit grossen Datenmengen möglich sind. Trotzdem wird der Zugang zu den Daten restriktiv behandelt, selbst wenn es sich – wie im Fall der europäischen (und einiger US-Partner) – um Public-Domain-Daten handelt. So sind Massendownloads von Datensets direkt von Google Books bisher nicht erlaubt bzw. erfordern bei grösseren Sets ein separates Agreement der betreffenden Institution mit Google. Die Implementierung innovativer Schnittstellen wie die IIIF-API sind ein weiteres Desiderat, ebenso wie die Möglichkeit, Kollektionen & Datensets in Google aufzubauen, zu pflegen und diese Daten zu nutzen oder nutzen zu lassen. Insbesondere Bibliotheken und andere kulturelle Institutionen könnten so einen noch grösseren Beitrag leisten, in den Digital Humanities neue Wege und Herangehensweisen an digitale Materialien zu eröffnen oder zu etablieren, sei es durch die Bereitstellung von Datensets für Hackathons, sei es durch eigene Entwicklungen in Labs und in Zusammenarbeit mit Forschenden.
|
|
Mitarbeiterin Abteilung Alte Drucke und Rara |